

As a Databricks partner, we don't just implement the platform for our clients; we also use it to run our own firm. That distinction matters. When we sit across the table from a client and recommend a unified data platform, we're drawing on direct, first-hand experience with the same architectural decisions, the same migration challenges, and the same operational payoffs they'll encounter. This post documents how we've built our internal analytics foundation on Databricks, why we made that choice, and what it looks like under the hood.
The Problem We Solved
As a professional services firm undergoing rapid growth, Origin faces some of the same challenges of our clients: a distributed data estate spread across multiple operational systems. Our CRM holds client and pipeline information. Our time-tracking platform holds utilization and delivery data. Financial actuals live in our accounting software. Each system does its job well, but none of them talk to each other, and none of them alone can provide a complete answer to the questions that matter most to running the business.
The result is a reporting environment that is naturally fragmented. Getting a complete picture of the business means pulling data from multiple sources, reconciling inconsistencies, and aligning definitions that don't always match across systems. At a certain scale, that fragmentation becomes a real constraint; decisions slow down, metrics drift, and meaningful analysis gets crowded out by the effort of simply assembling the data.
We needed a single, governed platform that could ingest data from all our operational systems, apply consistent business logic, and surface reliable metrics without requiring a data engineer to babysit it every morning. The answer: Databricks Data Intelligence Platform.
Why Databricks?
As a Databricks partner, it is both our platform of choice for client engagements and the foundation which we've built our own operations. A few of its core capabilities make it particularly well-suited for what we need.
Unity Catalog provides the governance layer that makes enterprise analytics reliable. For a firm handling sensitive client and financial data, the ability to define and enforce data access policies centrally across all users, all tools, and all workloads. Unity Catalog provides a unified "metastore" that governs who can see what, with full lineage tracking from raw ingestion to finished report.
The Lakehouse Architecture eliminates the tradeoff between a data warehouse optimized for SQL analytics, and a data lake optimized for flexible, large-scale processing. Databricks handles both in a single platform, which becomes increasingly valuable as analytical workloads grow in complexity and variety.
A broad integration ecosystem means Databricks connects cleanly with the operational systems businesses already use like CRMs, time-tracking platforms, financial systems, and BI tools, making it straightforward to consolidate data that would otherwise remain siloed.
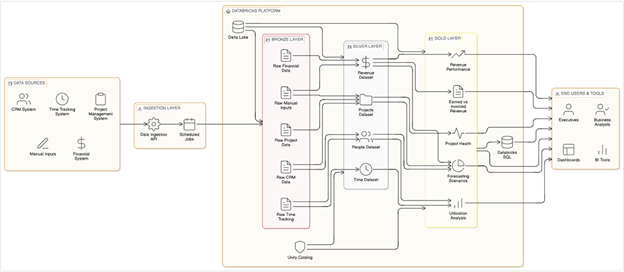
The Architecture: How It's Actually Built
Our internal data platform follows a Medallion Architecture: a layered approach that progressively refines raw operational data into trusted, analytics-ready datasets. Here's how each layer functions in practice.
Bronze Layer: Raw Ingestion
The Bronze layer is the foundation. We ingest data directly from our operational source systems on a scheduled basis (our CRM, time-tracking platform, and financial systems) and land it in Delta Lake tables exactly as it arrives. There are no transformations performed and no business logic applied. This layer serves as our audit trail: an immutable record of what every source system said, and when it said it.
If a number ever looks wrong upstream, Bronze is where we go to investigate. It gives us the ability to replay history and reconstruct any downstream dataset from first principles.
Silver Layer: Cleansed and Conformed Data
The Silver layer is where raw data becomes trustworthy data. Here we apply deduplication, standardize formats, resolve entity references (connecting a time entry to the correct project and the correct client, for example), and enforce the shared definitions that make cross-functional reporting possible.
This is one of the most important investments we've made. Codifying definitions and requirements such as...
- “What constitues a billable hour?”
- “How do we recognize revenue on a time-and-materials engagement?”
- “Which pipeline stage must a project reach before it appears in delivery reporting?”
...remove ambiguity from the business. These bedrock definitions no longer live in someone's head or in a cell comment buried in a spreadsheet. They live in governed, version-controlled code.
Gold Layer: Business-Ready Analytics
The Gold layer is what the business actually consumes in production. Living on top of Silver, these are purpose-built datasets and views that answer our most operationally critical questions:
- Revenue Actuals vs. Invoiced: How much have we earned versus billed? Where are the gaps?
- Project Health: Are engagements on track against budget and timeline?
- Capacity and Demand: How does forecasted demand map against available capacity over the next 90 days?
- Practice Performance: How are different service lines trending across revenue, delivery, and growth?
Gold layer datasets are stable, tested, and trusted.
Serving Layer: Getting Data to Decision-Makers
The final step is delivery. Our Gold layer feeds Power BI dashboards for operational reporting and Python-based analyses for more complex modeling work. Because every tool draws from the same governed source, there is no version divergence. One of the practical advantages of this architecture is flexibility. The same Gold layer can just as easily serve clean data feeds into Excel or other tools as reporting needs evolve, without any changes to the underlying platform.
The Operational Benefits
The shift to Databricks as our central analytics platform has had concrete, measurable effects on how we operate. Here are the benefits Origin now enjoys:
A single source of truth. Metrics no longer vary depending on who pulled the report and when. Utilization, revenue, and project data are consistent across every tool and every stakeholder. Debates about whose numbers are right have (almost entirely) disappeared. Multiple people can work from the same centralized data simultaneously. There's no locking, no version conflicts, no wondering whether you're looking at stale numbers.
Faster, more confident decision-making. Ad-hoc analysis that previously required building a new spreadsheet from scratch, pulling exports, cleaning data, and writing formulas. All of this effort can now be achieved in minutes working against a dataset that is already clean and current. Leadership spends less time preparing for conversations and more time having them.
Reduced operational risk. When a system of record is a file on someone's laptop, the business is one arrant deletion or corrupted formula away from a significant problem. A governed platform with versioned data, access controls, and lineage tracking is simply more durable.
Clear lineage and auditability. Every metric on a dashboard can be traced back through Gold, to Silver, and down to the raw API call in Bronze. When a number looks off, we follow the chain and track down the reason why.
Tool flexibility. Because the data lives in one governed platform, we can point any tool at it. Power BI for executive dashboards; Python notebooks for deeper analysis; a clean feed into Excel for quick extemporaneous number crunching; an API for automation with our custom .NET / Azure backend systems. The platform is the backbone; the consumption layer is a choice.
Scalability without rework. As we've grown, our data platform has evolved along with us. Adding a new data source, a new metric, or a new report does not require rebuilding anything; it simply entails further building upon an established, well-structured foundation.
A template for client engagements. Perhaps the most underappreciated benefit of operating Databricks internally is that it has made Origin materially better at implementing it for clients. We understand the edge cases, the governance decisions, and the organizational change management involved from direct experience.
What We've Learned
Building out this platform for ourselves has been as instructive as implementing it for clients. A few things stand out.
Consolidating data from disparate systems into a single analytical layer changes how leadership engages with the business. The conversations shift from reconciling numbers to what those numbers mean. That's not a small thing for a fast-moving organization!
What's Next
We're actively exploring Lakebase to close the loop between analytics and operations. The goal is write-backs, modifying a booking or updating a project status and seeing that change reflected in our Gold Layer reporting. That kind of tight feedback loop turns a reporting platform into an operational one.
A Platform You Can Build On
Operating Databricks internally has made us more effective partners for our clients. The decisions we've had to make about governance, data modeling, and balancing flexibility with consistency are the same ones our clients face. As a Databricks partner, we've seen firsthand how this architecture scales, both for our clients and for ourselves. The value isn't in replacing any one tool; it's in creating a foundation where your data works together instead of living in silos. If your business intelligence today depends on stitching together exports from five different systems...trust us...there's a better way to do it.
If you’re interested in understanding how your organization can leverage Databricks to transform its relationship with analytics and what capabilities it can provide to your business – let’s talk!
.svg)