

Azure Document Intelligence (formerly Form Recognizer) makes it possible to extract structured text, tables, and key-value pairs from complex documents - PDFs, contracts, invoices, financial statements, and more. But extracting is only half the battle. To turn that raw output into something an LLM can reason over, you need smart chunking strategies to unlock clean, retrievable context from extracted documents.
In this post, we’ll explore how to chunk such extracted outputs, what to watch out for, and how contextual expansion can help deliver more coherent answers.
Why Chunking Matters
When working with extracted text from Azure DI, you immediately run into practical constraints and challenges:
- Token limits: Embedding models and LLMs have maximum context sizes. Huge documents must be broken down.
- Context fragmentation: If a chunk cuts through a clause or table row, meaning can get lost.
- Retrieval noise: Bad chunking can return irrelevant text, making LLM responses weaker.
- Structural disconnect: Without respect for document structure (tables, paragraphs, sections), relations between pieces may get broken.
Smart chunking ensures that each unit is self-contained enough to make sense, searchable, and rich enough in context. The downstream retrieval and answer generation becomes more reliable when your chunks are well designed.
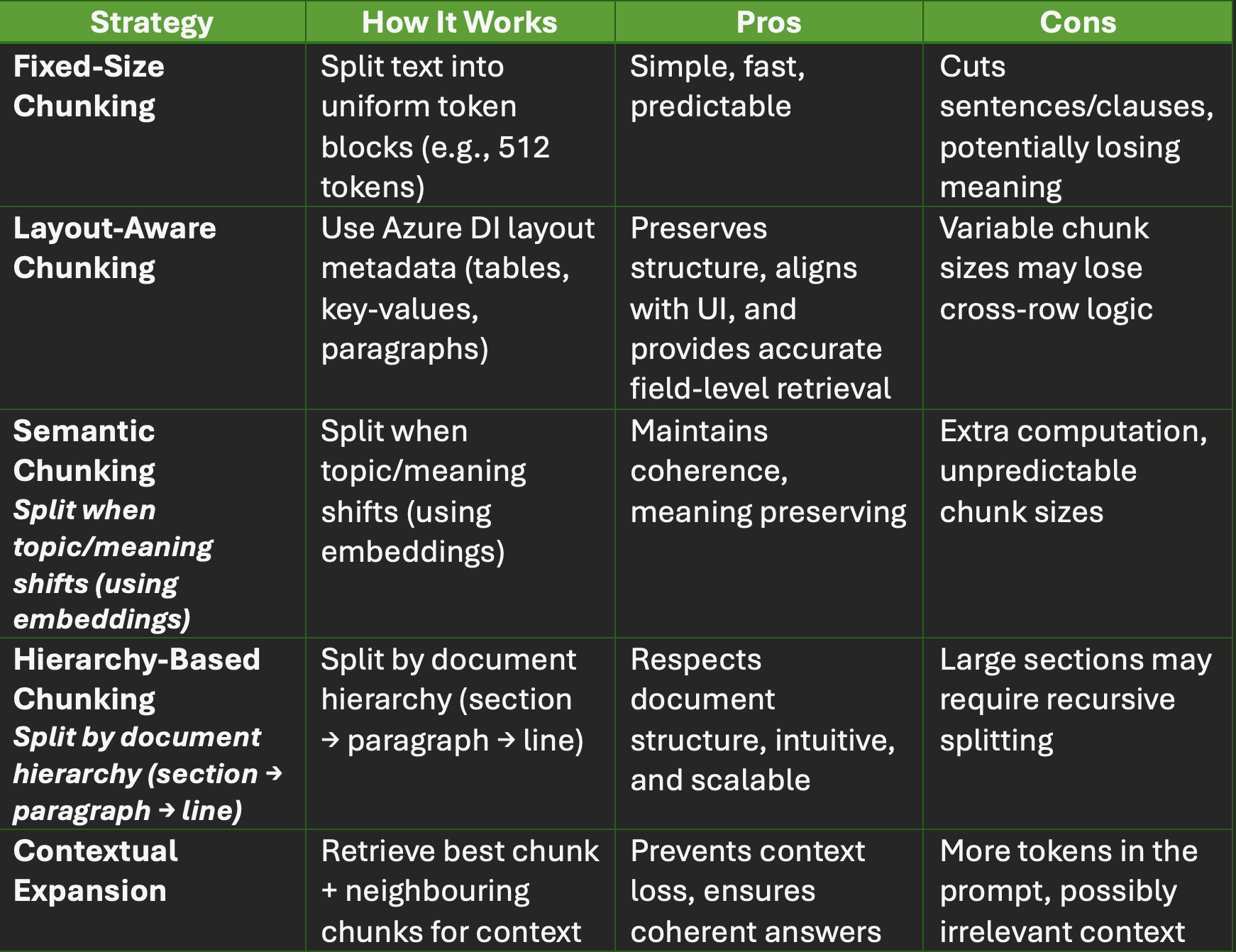
Key Chunking Strategies
Below are several strategies suited for Azure DI, including when to use it, when it works best, and pitfalls to keep in mind.
1. Fixed-Size Chunking
How it works: After extracting text, simply slice it into uniform token-based blocks (e.g. 512 or 1024 tokens), regardless of structure or semantics.
When to use: As a baseline or simple fallback, especially in homogeneous document collections (e.g. plain text reports).
Pros: Very easy to implement; predictable sizes; works as a “safe starting point.”
Cons: May cut through logical boundaries (e.g. breaking a sentence, splitting table rows), which can degrade semantic coherence.
Example: You have a 20-page technical report. You slice every 512 tokens. A sentence like “The liability clause shall terminate upon breach of Section 4.2, unless…” might get split between two chunks, making context harder to interpret.
2. Layout-Aware Chunking
How it works: Use the layout metadata Azure DI returns (tables, bounding boxes, form fields) to decide chunk boundaries.
- Each table row becomes a chunk.
- Each key-value (form field) becomes its own chunk.
- Sections like header, body, footer become chunks.
When to use: Highly structured documents—like invoices, purchase orders, tax forms, receipts.
Pros: Maintains direct mappings to the original document layout; easy to highlight in UI; queries can target table rows or fields directly.
Cons: Chunk sizes will vary; some logical relationships crossing rows/sections might be lost.
Example: In a contract, chunk into:
- Confidentiality & Non-Disclosure clause
- Payment & Billing terms
- Termination & Notice clause
- Dispute resolution & jurisdiction
Queries like “What’s the notice period?” directly retrieve the termination chunk.
3. Semantic Chunking
How it works: Instead of dividing by size or layout, break when the topic or meaning transitions. Use embeddings or similarity metrics to detect boundaries.
- Encode sentences/phrases.
- Slide window or clustering to identify drops in similarity.
- Start new chunk when thematic shift is detected.
- When to use: Documents like contracts, policies, or multi-topic reports, where meaning matters more than rigid structure.
Pros: Chunks align with meaning and preserve cohesion within each unit.
Cons: Requires extra computation (embedding checks, clustering); harder to control chunk sizes.
Example: In a contract, chunk into:
- Queries like “What’s the notice period?” directly retrieve the termination chunk.
- Confidentiality & Non-Disclosure clause
- Payment & Billing terms
- Termination & Notice clause
- Dispute resolution & jurisdiction
4. Hierarchy-Based Chunking
How it works: Leverage the hierarchical structure (page → section → paragraph → line) from Azure DI. Use top-level boundaries first. If a section is too big, split it further recursively.
- Use section or header markers to create chunks.
- If section is too long, break down to paragraphs, then sentences.
When to use: Complex documents, reports, white papers, multi-section technical documents.
Pros: Respects document organization, intuitive for humans and models alike.
Cons: If a section is very large, you need recursive splits; boundary detection depends on consistent structure.
Example: A financial report: A question like “What was net cash from operations?” will point you to Cash Flow Statement (and possibly sub-paragraphs).
- Chunk A: Executive Summary
- Chunk B: Balance Sheet & Assets
- Chunk C: Cash Flow Statement
- Chunk D: Notes & Disclosures (split further if too big)
5. Contextual Expansion (Smart Retrieval)
How it works: At query time, retrieve not just the best chunk but also adjacent chunks (neighboring context) to preserve continuity.
- Retrieve top-k chunk(s) from vector index.
- Also fetch chunks immediately before and/or after in sequence.
- Concatenate or feed them together for answer synthesis.
When to use: Any documents where clauses or ideas span across chunk boundaries—contracts, legal texts, multi-chunk narratives.
Pros: Helps avoid cutoff context or missing continuity; more coherent answers.
Cons: More tokens in prompt (neighbor chunks may not always be relevant). Needs attention to token budge.
Bringing It All Together: Hybrid Approaches
Rarely will one strategy suffice. In practice, you’ll often use hybrids:
- Layout-aware + semantic: use layout for table fields and semantic for narrative text.
- Hierarchy + contextual expansion: split by sections, then expand during retrieval.
- Fixed-size fallback within overly long sections that defy structure.
By experimenting, measuring retrieval accuracy, and monitoring downstream LLM answer quality, you’ll converge toward a strategy that balances coherence, relevance, and prompt efficiency.
Ready to Get Started?
If you’re building a retrieval-augmented system using Azure DI + embeddings + LLMs, Origin Digital can work with you to build a production-grade version. Let us know your document domain (contracts, invoices, reports, forms, among others) and the stack you’re using, and we’ll partner together to do the following:
- Design and test chunking strategies for your document types
- Set up the vector store + retrieval logic
- Integrate with your LLM pipeline so that contextual expansion gives you the best possible answers
.svg)